在網站優化的過程中,你是否曾經好奇:為什么某些頁面可以被搜索引擎收錄,而某些卻不能?其實,這背后就隱藏著一份重要的“指令文件”——robots.txt。那么,什么是robots協議?它的存放位置是哪里?又該如何正確編寫和使用?別急,今天我們就來全面解析!

什么是robots協議?
robots協議,也叫做網絡爬蟲協議(Robots Exclusion PRotocol),是網站管理員用來指示搜索引擎爬蟲應該如何抓取并索引網站內容的一種規則。這些規則通常以robots.txt文件的形式呈現,幫助網站管理者控制搜索引擎的抓取行為。
robots.txt文件的存放位置
robots.txt文件需要放置在網站的根目錄中(例如:www.exAMPle.com/robots.txt)。這是因為搜索引擎爬蟲訪問網站時,通常會首先查找根目錄下是否存在這個文件。如果沒有這個文件,爬蟲通常會默認抓取整個網站。
基本格式與使用技巧
robots.txt文件的語法非常簡單,主要包含兩個核心指令:`User-agent`(指定爬蟲類型)和`Disallow`(禁止爬取的路徑)。以下是一個典型的例子:
```
User-agent: *
Disallow: /private/
```
- User-agent: `*`表示適用于所有搜索引擎爬蟲。
- Disallow: 指定禁止爬取的文件夾或路徑,比如這里禁止爬取`/private/`目錄。
使用技巧:
1. 檢查文件的正確性: 使用Google Search Console等工具驗證robots.txt文件是否編寫正確。
2. 細化爬取規則: 對于特定搜索引擎,可以針對不同`User-agent`設置個性化指令。
3. 防止意外封禁: 確保沒有誤禁止重要頁面的爬取,比如首頁或文章目錄。
robots協議的作用
1. 保護隱私: 防止特定文件夾(如用戶數據或后臺管理頁面)被抓取。
2. 節約爬取資源: 通過對爬蟲行為的限制,集中抓取重要頁面。
3. 提升SEO效果: 幫助搜索引擎專注于優質內容,提高整體的排名表現。
總結與互動
robots.txt文件看似簡單,卻對網站的SEO優化起著至關重要的作用。如果你的網站尚未配置robots.txt,不妨馬上行動起來,為你的SEO表現助力!
你是否成功配置過robots.txt?或者在設置時遇到了哪些問題?歡迎在評論區分享你的經驗,我們一起來討論!
標簽:
本文鏈接:http://m.www9463.cn/xinwendongtai/1630.html
版權聲明:站內所有文章皆來自網絡轉載,只供模板演示使用,并無任何其它意義!

如何查看網站的robots協議,網站如何正確設定robots協議
農業機械設備灌溉網站源碼+手機端自適應

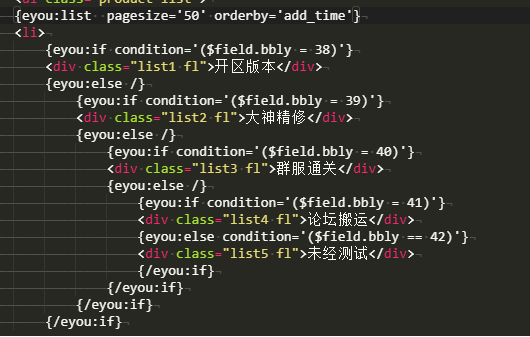
易優cms能做價格區間的篩選嗎
eyoucms更新了系統之后報錯$(...).slide is not a function
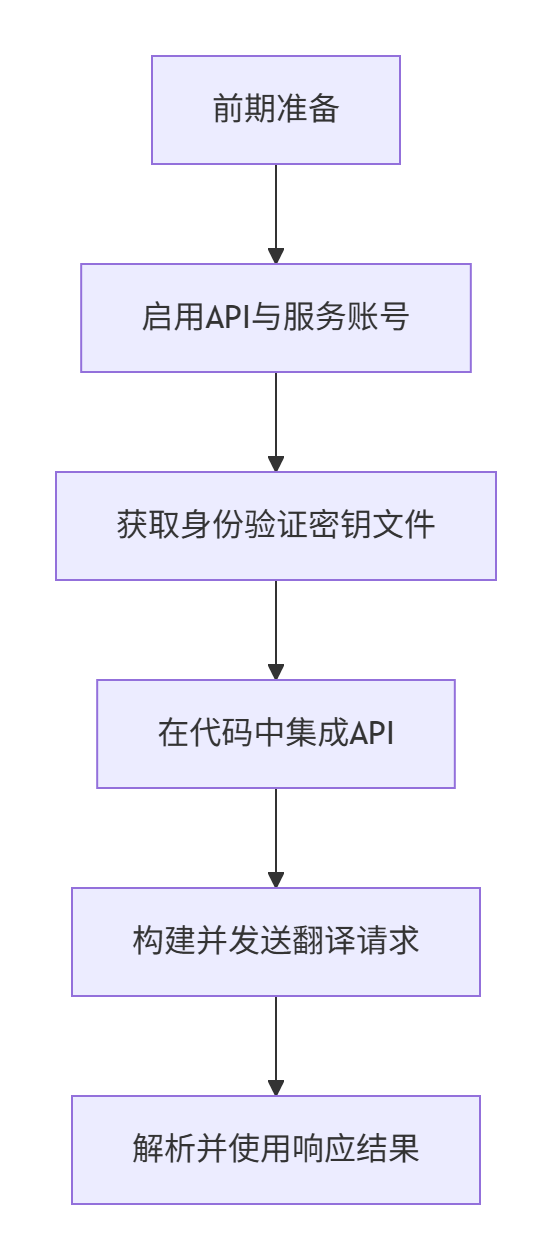
如何使用google API翻譯
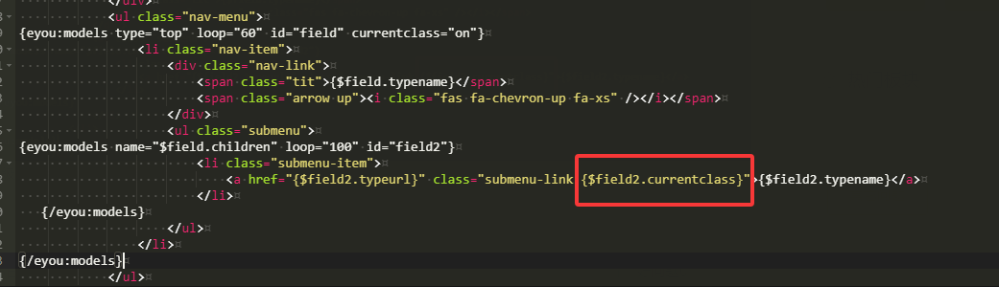
eyoucms導航的二級欄目怎樣增加高亮?

eyoucms搜索列表頁支持artpagelist瀑布流嗎
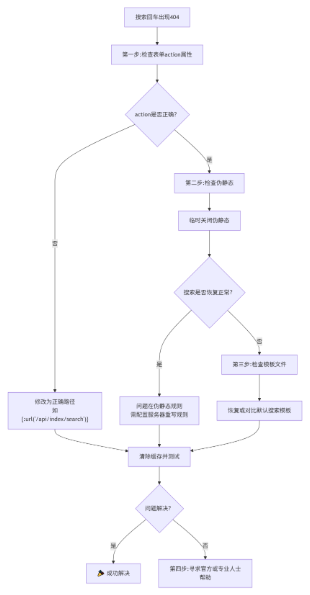
eyoucms搜索功能異常回車搜索出現404錯誤怎么解決?
網站地圖一般多久更新一次?
網站分類目錄導航網站源碼+手機自適應

易優模板文件不存在:./template/pc/lists_tags.htm如何解決?
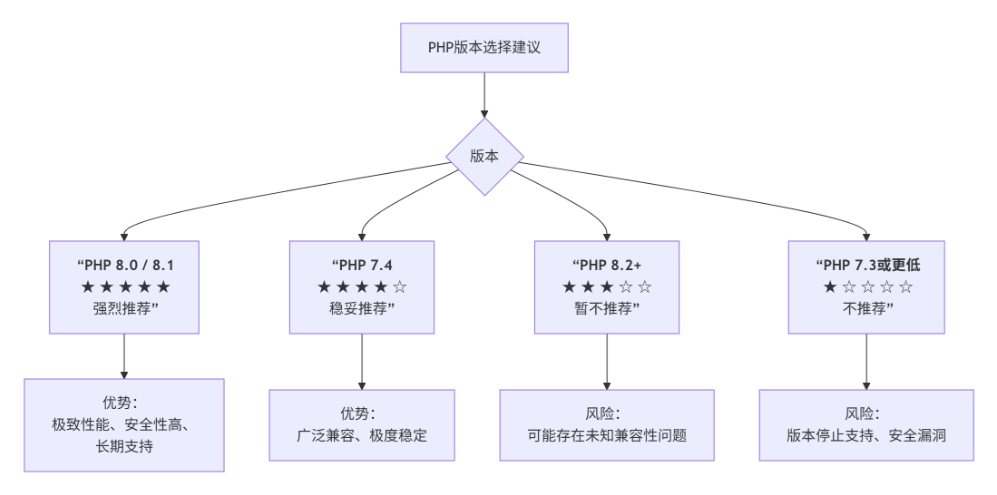
易優AI版推薦使用的數據庫版本和PHP版是什么?