在網絡世界中,是否常聽到“網絡爬蟲”這個詞,卻對其含義依然一知半解?今天,我們將揭開網絡爬蟲的神秘面紗,幫你深入了解它的分類、組成、工作原理以及搜索策略。通過這篇文章,你將更加清晰地了解網絡爬蟲在互聯網中的重要作用。
什么是網絡爬蟲?
網絡爬蟲(Web Crawler),也稱為網絡蜘蛛,是一種自動化程序,能夠按照給定規則在互聯網上抓取頁面內容并進行數據提取。它是搜索引擎得以運轉的核心技術,驅動了如今的信息檢索服務。例如,當你在搜索引擎中敲入一個關鍵詞時,是網絡爬蟲讓這些信息觸手可及。

網絡爬蟲的分類
網絡爬蟲可以細分為以下幾類:
1. 聚焦爬蟲:只抓取特定主題相關的內容,例如財經新聞或科技文章。
2. 增量爬蟲:只爬取網站的新增或更新內容,提升效率。
3. 廣度優先爬蟲:從若干初始網頁開始,按照鏈接關系遞歸抓取所有頁面。
網絡爬蟲的組成
一個完整的網絡爬蟲通常包括以下核心模塊:
URL調度器:負責管理待抓取的URL列表。
頁面下載器:抓取網頁內容并存儲。
數據解析器:對抓取到的網頁進行解析并提取有效信息。
存儲模塊:對爬取的數據進行分類存儲,便于后續處理。
網絡爬蟲的工作原理
網絡爬蟲的工作大體上可以分為以下幾個步驟:首先,它從一個種子URL開始,通過頁面下載器抓取網頁內容。隨后,解析這些網頁并提取新的URL,加入到URL調度器中,形成一個迭代的抓取過程。最終,爬蟲會將爬取的數據存儲并提供給數據分析工具。
常見的搜索策略
爬蟲的效率常受搜索策略影響,以下是兩種常見策略:
1. 深度優先策略:優先抓取鏈接級別較深的頁面,適合抓取特定主題內容。
2. 廣度優先策略:優先抓取鏈接較淺的頁面,適合收集全面的信息。
正是這些策略的靈活運用,使得搜索引擎能夠為用戶提供精準的結果。
文章總結:
通過今天的講解,你是否對網絡爬蟲有了全新的認識?歡迎在評論區分享你的想法,或者提出你的疑問!如果你對網絡爬蟲技術感興趣,也可以挖掘更多相關知識。
網絡爬蟲是互聯網信息的無聲推動者,它改變了我們獲取信息的方式,讓數據觸手可及。在未來,這項技術會如何發展?或許答案正掌握在你的手中。
標簽:
本文鏈接:http://m.www9463.cn/xinwendongtai/1684.html
版權聲明:站內所有文章皆來自網絡轉載,只供模板演示使用,并無任何其它意義!
農業機械設備灌溉網站源碼+手機端自適應

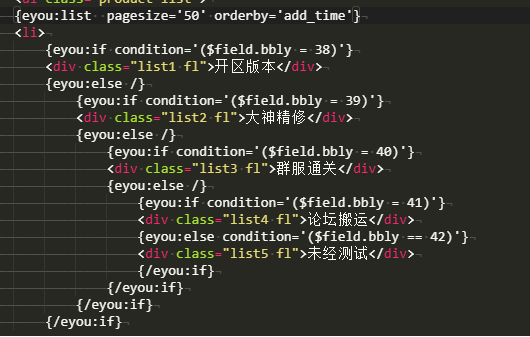
易優cms能做價格區間的篩選嗎
eyoucms更新了系統之后報錯$(...).slide is not a function
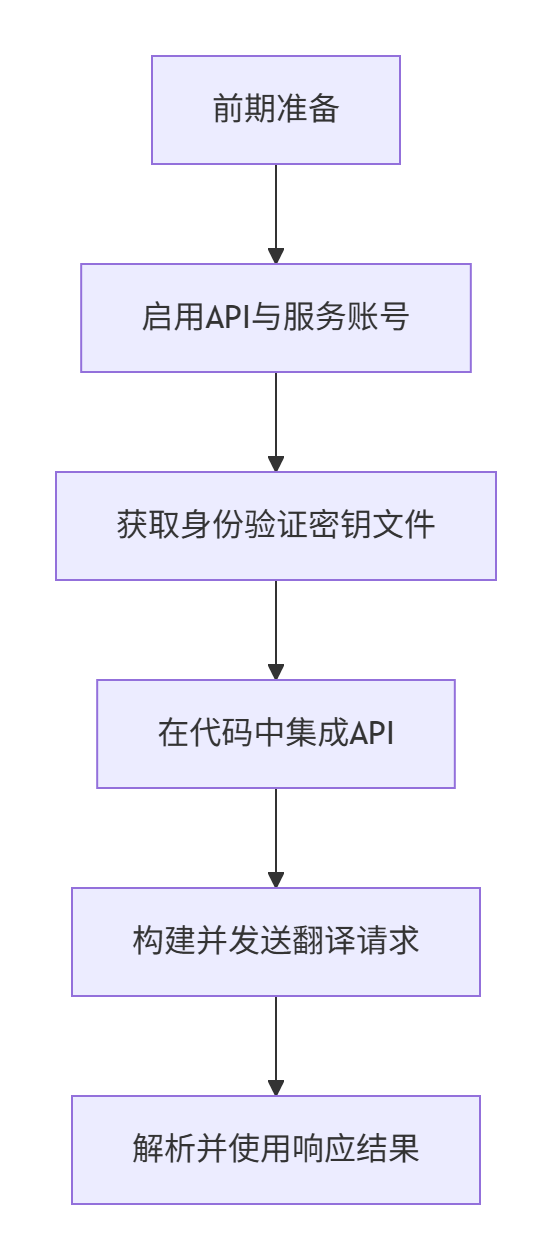
如何使用google API翻譯
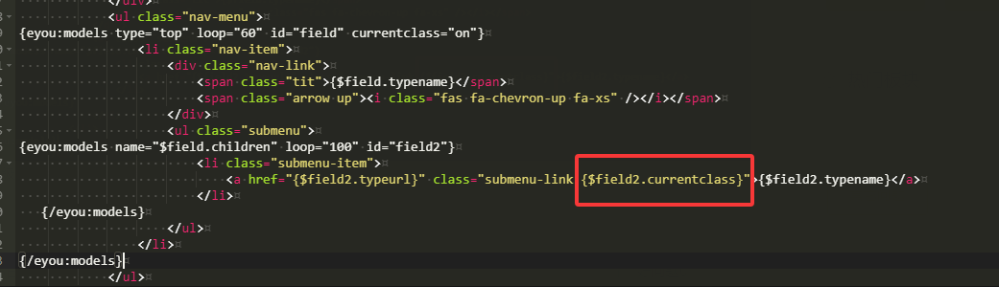
eyoucms導航的二級欄目怎樣增加高亮?

eyoucms搜索列表頁支持artpagelist瀑布流嗎
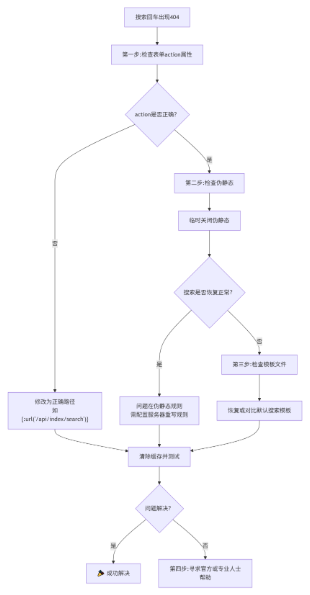
eyoucms搜索功能異常回車搜索出現404錯誤怎么解決?
網站地圖一般多久更新一次?
網站分類目錄導航網站源碼+手機自適應

易優模板文件不存在:./template/pc/lists_tags.htm如何解決?
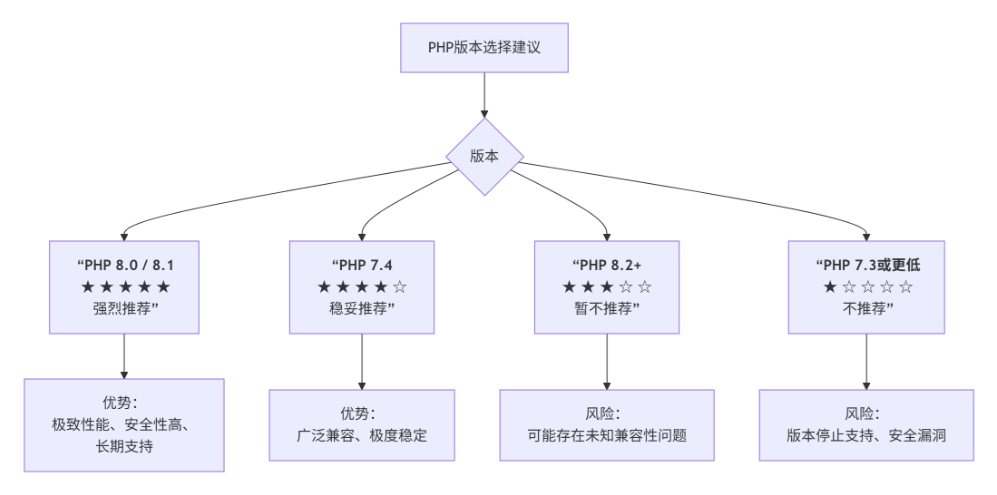
易優AI版推薦使用的數據庫版本和PHP版是什么?

eyoucms當前頁的url調用標簽怎么調用